Examples > Text statistics > Class members
In the previous examples locale variables were used, which are declared inside of an action and can be passed to other productions or tokens as a parameter. In this project class variables are used. The declaration of a class or member variable is made on a special page of the TETRA user interface. Such variables can be accessed immediately inside of each action of all productions and tokens (and member function see below). The value of a member variable can be changed in one action and immediately is in disposal of other parts of the program.
In the actual project for example there is an integer member variable m_iChars, which stores the number of recognized characters. In each token action this variable will be augmented by the number of characters, which is recognized by the token.
The declaration of m_iChars is done on the element page.
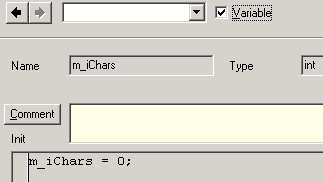
To declare a variable, you have to enable the according check box in the toolbar. Otherwise m_iChars would be interpreted as the name of a member function.
The type of the variable is set to int in the Type field.
The text field now is entitled: Init. For variables this field may remain empty, but it also can be used, to initialize the variable. The initialization is done every time a new text transformation starts.
Here m_iChars gets the value 0. This is the default value, which the variable would have obtained too without explicit initialization. But to initialize the variable is a better programming style. If code for a parser class is exported the lack of an initialization can lead to errors, because in c++ integer variables don't get an initial value automatically.
Other member variables to count lines, words etc. are declared in the same manner as m_iChars.
A special case is m_mAbbr. This variable has the type mstrstr and is initialized by a number of expressions, which are abbreviations, if they are followed by a dot.
m_mAbbr["am"] = "";
m_mAbbr["Am"] = "";
m_mAbbr["usw"] = "";
m_mAbbr["etc"] = "";
...
This list is needed, when counting sentences to distinguish dots, which are marking the end of a sentence and dots, which belong to an abbreviation. Because the list by no means is complete, the counting of sentences will remain uncertain.
Each of the elements of the list is assigned an empty string. These values aren't needed. In this project only the property of the map is used, that searching for a key is very quick, because the keys are in sorted order automatically.
Further there is a member function PrintResult:
out << "Text statistics:\n";
out << m_iLines << "\tlines\n";
out << m_iChars << "\tcharacters\n";
out << m_iWords << "\twords\n";
out << m_iNumbers << "\tnumbers\n";
out << m_iSentences << "\tsentences\n"
It prints the formatted result of the counting at the end of the program.