User interface > Main menu > Menu: Options > Project options > Parser/Scanner > Global scanner
On the page Parser/Scanner of the project options three check boxes exists, by which you can make some fine-tuning of the scanning process.
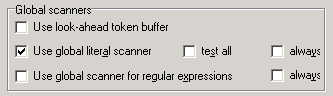
It is recommended, to leave the default settings, with activated global scanner for literals. If you don't have special reasons to change the scanning process, you can leave the default settings and you don't have to read the following explanations.
The buffering of the look-ahead tokens can accelerate the execution of a project if makes heavy use of look-ahead's. This isn't the case mostly.
The other options in this box control of the sets of token which are tested respectively in the current position of the grammar. The speed of the parser and the error probability are influenced by these sets. Larger token sets slow down the parser and increase the probability that a token is found that doesn't match to the grammar. The latter may be wanted in certain cases, e.g. inside of a look-ahead.
If no global scanners are used, then only the tokens are looked for, which just can follow in accordance with the grammar. If however global scanners are used, then all literals can be tested always or they are tetsted only,if a at least one literal can follow according to the grammar. Similar for the regular expression: either all are testet always or all are tested, if at least one can follow.
Note: Internally there is a third Scanner, which can be global or local. It's the scanner for ignorable characters. Whether this scanner is local or global is determined by the setting of ignorable characters in the local options.
This once again with some more details:
There are three steps of evaluating the next token corresponding to the three kinds of scanners. Beginning at the actual position in the input has to be evaluated
1. whether ignorable characters are following, and then
2. whether a literal token is following or,
3. whether a token defined by a regular expression is following
These three tests can either be done by a single global scanner, or by local scanners. The use of one global scanner is the traditional method, applied by all parser generators hitherto. The use of local scanners is based on the idea, to test only those candidates for the next token, which are part of the actual alternatives. For example: to test the following structure it is necessary to decide, whether an a or a b token exists at the actual position
( a | b ) c d
A local scanner will test exactly this. A traditional global scanner in contrast will test all token of a grammar, that means at least a, b, c and d token. The result will be the same for both types of scanner. The difference lies in the speed and the expense. When using local scanners the speed will be higher, but a bigger amount of storage is needed.
The result of the text analysis also can be influenced by the choice of global or local scanners. By use of a global scanner the probability of conflicts between different token is greater than by use of local scanners, where only a little set of tokens compete with each other. This is the reason why there is the additional possibility to limit testing on the currently expected tokens even if a global scanner for literals is used.
Example:
Text: "int int"
Produktion: "int" ID
Token ID: \w+
If all literal tokens are always tested, the second occurrence of "int" isn't recognized as an ID. The literal token "int" is rather recognized once more. So the text cannot be parsed. This is desired if the text e.g. is C++ code. A variable may not have the name of a variable type.
Text: "Sir Sir"
Produktion: "Sir" NAME
Token NAME: \w+
Look into the phone book and you will find the name "Sir". So the salutation "Sir Sir" is definitely correct. It only is recognized if you don't test on all literal tokens.
Rule of thumb:
All literals should be tested for formalized languages with defined key words at significant positions. Only the expected literals should be tested otherwise The local options also can be adapted respectively, if necessary.
Conflicts, which can result from the use of a global scanner, can be the cause of error messages like
Matching but not accepted token: ...
At the description of this message an example is presented.
A further example of the effects of the scanner options is given at the explanations for the look-ahead production.