User interface > Main menu > Menu: Options > Project options > Parser/Scanner > Ignorable characters
Usually spaces within the source text of a program are irrelevant, and when, the TextTransformer looks for the start of a token, it will simply ignore them. Other separators like tabs, line ends, and form feeds may also be declared irrelevant.
Example:
A Production for the sum of two terms can be easy written as:
Sum = Term "+" Term
This rule not only shall recognize a text like:
"23+4"
but also
"23 + 4" and " 23 + 4" etc.
The spaces between the numbers and the plus operator are irrelevant and should be skipped. If the space were not set as irrelevant, additional token for the gap between the terms and the operator had to be defined. For example:
Space = "[\n\r\t ]*" (linefeeds line breaks, tabs and spaces).
The production above had to be reformulated:
Sum = Term Space "+" Space Term
Depending on the activation of the check box Regex, the ignorable characters will be defined as a list of characters or as a regular expression.
Definition of the ignorable characters as a list of characters
Spaces, linefeeds, line breaks and tabs are set as ignorable characters per default. They can be removed or added to the list of ignorable characters simply by clicking the accordant check box.
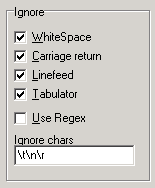
Manually other character can be added too.
Definition of the ignorable characters as a regular Expression
In spite of a list, you can define the ignorable characters also by means of a regular expression. To do so, the box Regex must be activated. The text of the edit field now will be interpreted as a regular expression.
For example the expression "\s*" could be set. Then all characters of the character set \s would be skipped. That's about the same as a character list, where all check boxes are activated. An example that makes more sense is:
(\s|//[^\r\n]*)*
By means of this expression not only the spaces will be skipped, but also line comments.
You also can set the name of an already defined token into the edit field. Now this token defines the ignorable characters.
If the check box regex is activated and the text in the edit field only consists of literal characters, the text will be interpreted as the name of a token.
Remark: A regular expression, that defines the ignorable characters, will automatically be included into parenthesis and preceded by the anchor "\\A", to assert, that the skipped section always will begins at the actual text position.
Remark: When you use a list of ignorable characters, it is possible to access the skipped characters, which follow on a SKIP node, by xState.str(-1). If you use a regular expression, this is not possible.