Besides some token directly defined inside of the productions and the STRING token, in this example there are two groups of token. The first consist of:
LINE_COMMENT //[^\r\n]*
PREPROCESSED #[^\r\n]*
USING using [^\r\n]*
While they begin differently, they all end with [^\r\n]*. The last expression describes an arbitrary repeat of characters, which are not line endings. So the group of token describe sections of text, beginning with "//" or "#'" or "using" and extending to the end of the line. A c++ programmer recognizes immediately, that line comments, preprocessor directives and using directives are described.
The tokens of the second group consist in:
DECLARATOR
DESTRUCTOR
They are beginning with an expression similar to:
(((\w+::)*\w+)::)?(\w+)
This expression may appear unnecessarily complicated at first. The simple expression:
(\w+::)*\w+
also would recognize texts like:
Name
Class::Name
Class::Subclass::Name
etc.
that are names and class methods.
But the complicated form of the expression allows the access of sub-expressions. Each pair of parenthesis matches a section of the text, matched by the expression as a whole. This section can be accessed in the interpreter. Which section of text is related to which parenthesis can be displayed by a tool integrated in the TextTransformer: menu: Help->Regex test.
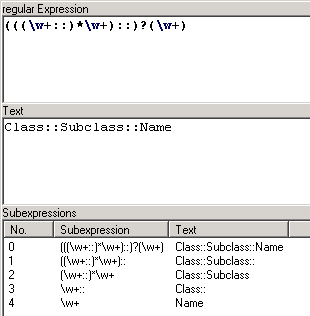
From the lower table you can see, that the sub-expression with the index 2 matches the scope, and the sub-expression with the index 4 the name of a class method. This is used in the guard project, to write these strings into different member variables:
{{
m_sScope = xState.str(2);
m_sName = xState.str(4);
}}
These variables are defined on the element page of the IDE. They are used in the functions print_at_enter and print_at_exit, described later.
The complete definitions are:
DESTRUCTOR ::= (((\w+::)*\w+)::)(~\w+)
DECLARATOR ::=
(((\w+::)*\w+)::)(\w+) \// scope(s) and name, e.g.: CSub::CClass::Func
\s* \// optional spaces
\([^)]*\) // parameter, e.g..: ( int xi )
Notice, that complex expressions can be written and commented into different lines.
Although the tokens are quite similar, TETRA can decide which token matches the text best:
CguardParser::~CguardParser()
will be recognized as DESTRUCTOR and
CguardParser::SetIgnoreScanner()
will be recognized as DECLARATOR.
TETRA uses an algorithm, by which the longest match will be preferred.
By this you can avoid limitations that the top down analysis of TETRA would have otherwise.