User interface > Main menu > Menu: Options > Project options > xerces DOM
The options which have to be set for a standalone XML document are in the upper half of the dialog page. Such a document doesn't depend on a DTD.
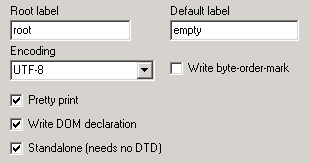
The shown options produce a document, this looks as follows:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
<root>
...
</root>
Root label
Here the root tag is defined. In the example it is called "root".
Default label
Each tag of an XML document must have a name. This name is the label of a dnode. To keep the analogy to the construction possibilities of node's, dnode's can be used without explicitly defined labels. Such dnode then gets internally the default label assigned automatically.
dnode dn("". "text");
then appears with the default label above as:
<empty>text</empty>
Before a parser is called in the generated c++ code, the default label has to be set. CTT_DomNode has a static method for this purpose.
dnode::SetDefaultLabel(L"default_label");
Encoding:
Xerces supports many encodings for the output of the XML documents, which are discussed below. However, only the ANSI character set (Windows 1252) is represented correctly in the working surface of the TextTransformer. ANSI or a different 8 bit encoding should therefore be used in the developmental stage of a project. Otherwise the text appears in the output window:
Encoding cannot be written into the output window of the IDE
If a project is executed by the transformation manager, the command line tool or the Delphi components, there isn't any restriction for the encoding.
Here some remarks copied from
http://xerces.apache.org/xerces-c/faq-parse.html
concerning the different supported encodings
ISO-8859-1 (aka Latin1)
For UNIX systems in countries speaking Western European languages, the encoding will usually be iso-8859-1
Windows-1252
The default character set on Windows systems is windows-1252 (ANSI), not iso-8859-1. While Xerces-C++ does recognize this Windows encoding, it is a poor choice for portable XML data because it is not widely recognized by other XML processing tools.
UTF-8
UTF-8 - like UTF-16 - covers the full Unicode character set, which includes all of the characters from all major national, international and industry character sets. This encoding - like UTF-16 - is more widely supported by XML processors than any others
Efficient. utf-8 has the smaller storage requirements for documents that are primarily composed of characters from the Latin alphabet.
UTF-16 (Big/Small Endian)
UTF-16 - like UTF-8 - covers the full Unicode character set, which includes all of the characters from all major national, international and industry character sets. This encoding - like UTF-8 - is more widely supported by XML processors than any others
UCS4 (Big/Small Endian)
EBCDIC code pages IBM037, IBM1047 and IBM1140 encodings
(Extended Binary Coded Decimals Interchange Code)
IBM1140
IBM037
IBM1047
When creating EBCDIC encoded XML data, the preferred encoding is IBM1140. The IBM037 encoding, and its alternate name, ebcdic-cp-us, is almost the same as IBM1140, but it lacks the Euro symbol.
Write byte-order-mark (BOM)
At some encodings a byte order mark (BOM) can be set at the beginning of a file.the mark tells in which order the bytes must be evaluated, if single characters consist in several bytes, like in UTF-16.
The BOM is written at the beginning of the resultant XML stream, if the output encoding is one of the following:
| • | UTF-16 |
| • | UTF-16LE |
| • | UTF-16BE |
| • | UCS-4 |
| • | UCS-4LE |
| • | UCS-4BE |
Such a mark also can optionally be used in UTF-8 to indicate the file as UTF-8 encoded. However, it isn't possible to set a BOM for UTF-8 per option automatically, since xerces doesn't support this. However, the BOM can be written by the following code in the program:
out << char(0xEF) << char(0xBB) << char(0xBF);
WriteDocument();
If a UTF-8 encoded file is read as an ANSI file, this mark appears as: .
Encoding |
Bytes |
UTF-8 |
EF BB BF |
UTF-16 Big Endian |
FE FF |
UTF-16 Little Endian |
FF FE |
Pretty-print
This formats the output by adding a newline carriage return and indented whitespace to produce a pretty-printed, human-readable form.
If this option is set and the document shall be written with a WriteDocument without parameters, it is required for some encodings - e.g. for UTF-16 - to set the option for a binary output too.
Write DOM-declaration
The line in the example above::
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
is the declaration of the document. If it shall not be written or be formulated explicitly in the program - for UTF-8 only -, then the checkbox can be deactivated.